


Computer Vision

Computer Vision
Our vision is to make robots being able to “see”, “understand” and “interact” with the environment. Towards this, designing an artificial visual system that is able to sense a dynamic environment at high-frame rate at low power consumption in order to be deployable under an embedded setting is of paramount importance.
As such, this theme of research focuses on how to design vision systems that can offer real-time performance at low power. We are interested in developing computer vision algorithms that can be mapped in an efficient way to the underlying hardware, as well as designing the hardware architecture itself that would allow an efficient implementation of the algorithm.
Human Pose Estimation on Embedded Systems
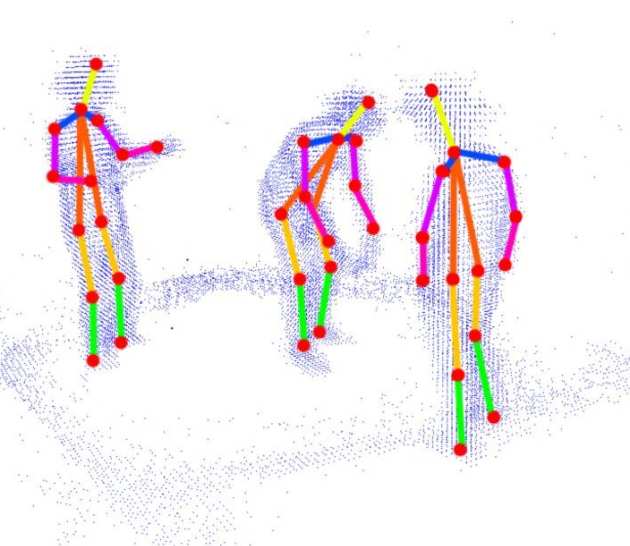 Human pose estimation refers to the process of detecting the positions of the joints of the human body from images or 3D data, in order to reconstruct the skeletal structure and extract information about body posture, motion and gestures. It is considered one of the major challenges in the field of Computer Vision and has been intensively studied, in the last few decades by the computer vision community, due to its fundamental importance in various scientific fields. Estimating the human pose, however, is an intricate and complex task, having led to the development of multiple implementations which while successful in accurately tracking the human body, are not suitable for deployment in systems with limited processing power (i.e. mobile devices, autonomous robots etc.) as they require substantial computing resources in order to reach the desired performance levels.
Human pose estimation refers to the process of detecting the positions of the joints of the human body from images or 3D data, in order to reconstruct the skeletal structure and extract information about body posture, motion and gestures. It is considered one of the major challenges in the field of Computer Vision and has been intensively studied, in the last few decades by the computer vision community, due to its fundamental importance in various scientific fields. Estimating the human pose, however, is an intricate and complex task, having led to the development of multiple implementations which while successful in accurately tracking the human body, are not suitable for deployment in systems with limited processing power (i.e. mobile devices, autonomous robots etc.) as they require substantial computing resources in order to reach the desired performance levels.
Towards this end, our group focuses on the development of a novel human pose estimation framework, capable of state-of-the-art accuracy and robust performance in unconstrained settings, while simultaneously taking into consideration, during the design phase, of the hardware characteristics and limitations of available embedded systems. The outcome of this effort will be the development of a flexible parameterizable model where a set of hyper-parameters can efficiently trade off between computational complexity and accuracy.
Simultaneous Localization and Mapping (SLAM) on Embedded Devices with Custom Harware
Real-time embedded scene understanding
 Real time scene understanding, a new field created by the fusion of real-time computer vision, object recognition and machine learning, is central to emerging applications in robotics, self-driving cars and augmented/virtual reality (AR/VR) . Algorithms in this field are key in enabling truly intelligent household robots, Level 5 autonomous cars, the next evolution of industrial robotics, a new paradigm of human-computer interaction and many more. At the same time the algorithms developed in this field are very computationally complex. Most of the research is done with high-end hardware including GPU acceleration which comes with high cost and power requirements. Meanwhile, a lot of the above applications require this technology to be integrated/embedded in mobile or low-power platforms as well.
Real time scene understanding, a new field created by the fusion of real-time computer vision, object recognition and machine learning, is central to emerging applications in robotics, self-driving cars and augmented/virtual reality (AR/VR) . Algorithms in this field are key in enabling truly intelligent household robots, Level 5 autonomous cars, the next evolution of industrial robotics, a new paradigm of human-computer interaction and many more. At the same time the algorithms developed in this field are very computationally complex. Most of the research is done with high-end hardware including GPU acceleration which comes with high cost and power requirements. Meanwhile, a lot of the above applications require this technology to be integrated/embedded in mobile or low-power platforms as well.
Clearly this demands a change in thinking, and a very promising avenue is custom heterogeneous and reconfigurable computing. In our group we investigate exactly that, designing custom hardware accelerators focusing on real-time embedded scene understanding and particularly on Simultaneous Localisation and Mapping (SLAM) in the context of visual sensors. SLAM is a family of algorithms that solve the problem of estimating an observer's position in an unknown environment, while generating a map of that environment using a geometric formulation. Our work so far has resulted in developing very high bandwidth streaming hardware architectures for both Tracking and Mapping in the context of a Semi-dense SLAM algorithm that enable state-of-the-art performance with an order of magnitude improvement in power consumption.
This way we can push the efficiency and performance much further than traditional computing platforms and enable the design of high quality, state-of-the-art visual SLAM in lightweight and agile robots such as UAVs and small ground robots which have applications ranging from rapid environment exploration to precision agriculture. The same hardware and principles can be applied in household and industrial robotics as well as in a lot of augmented or virtual reality applications. Our findings can also be utilised to design more power efficient self-driving cars which have to continuously monitor their environment for obstacles or other vehicles while tracking their own position with high accuracy, using a combination of radar, sonar and camera sensors.
SLAMSoC
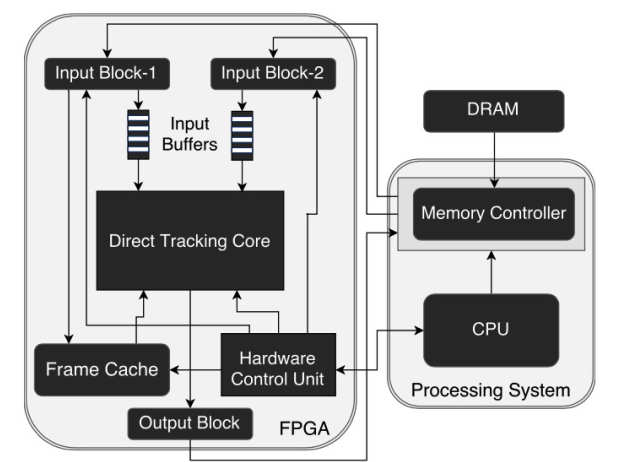
Simultaneous localization and mapping is the problem of using a series of observations of an environment to build a map of that environment while simultaneously keeping track of the observer's position in it. Moving SLAM algorithms into the embedded space with efficient, low-power designs can open the way to emerging new applications including autonomous robotics and augmented reality. Such applications will require an accurate and information rich reconstruction of the environment. In our lab we are interested in providing small to medium UAVs with SLAM capabilities so they can navigate and eventually interact with an unknown environment in an autonomous way. As such, the above approaches cannot be applied to the targeted application. Towards this goal we are investigating the use of a novel platform for this kind of problem, a hybrid embedded Field Programmable Gate Array System on Chip (FPGA-SoC).
Face Super-Resolution
 In many real-life scenarios, there is the need to enhance the spatial resolution of a human face in order to help with its tracking or recognition. Such cases appear when the subject is far from the camera resulting in images where the target face has resolution between 12x12 to 30x30 pixels. Even-though Face Super-resolution is still an active research field in image processing community, we are taking a different look at the problem and we impose real-time constraints on the embedded system (i.e. low power consumption) that would perform the super-resolution task. Our work achieves significantly better results from other state-of-the-art methods by coupling the deblurring and the registration process. Towards this direction, our group focuses on the computational aspects of the current algorithms as well as on the hardware characteristics of the available embedded platforms (i.e. SoC devices from FPGA vendors, Tegra K1 from nVidia) in order to accelerate such process and achieve real-time performance.
In many real-life scenarios, there is the need to enhance the spatial resolution of a human face in order to help with its tracking or recognition. Such cases appear when the subject is far from the camera resulting in images where the target face has resolution between 12x12 to 30x30 pixels. Even-though Face Super-resolution is still an active research field in image processing community, we are taking a different look at the problem and we impose real-time constraints on the embedded system (i.e. low power consumption) that would perform the super-resolution task. Our work achieves significantly better results from other state-of-the-art methods by coupling the deblurring and the registration process. Towards this direction, our group focuses on the computational aspects of the current algorithms as well as on the hardware characteristics of the available embedded platforms (i.e. SoC devices from FPGA vendors, Tegra K1 from nVidia) in order to accelerate such process and achieve real-time performance.