


Single-channel speech enhancement
Single-channel Online Enhancement of Speech corrupted by Reverberation and Noise
Consider the reverberant and noisy speech signal y(n). The general diagram of the enhancement system is shown below.
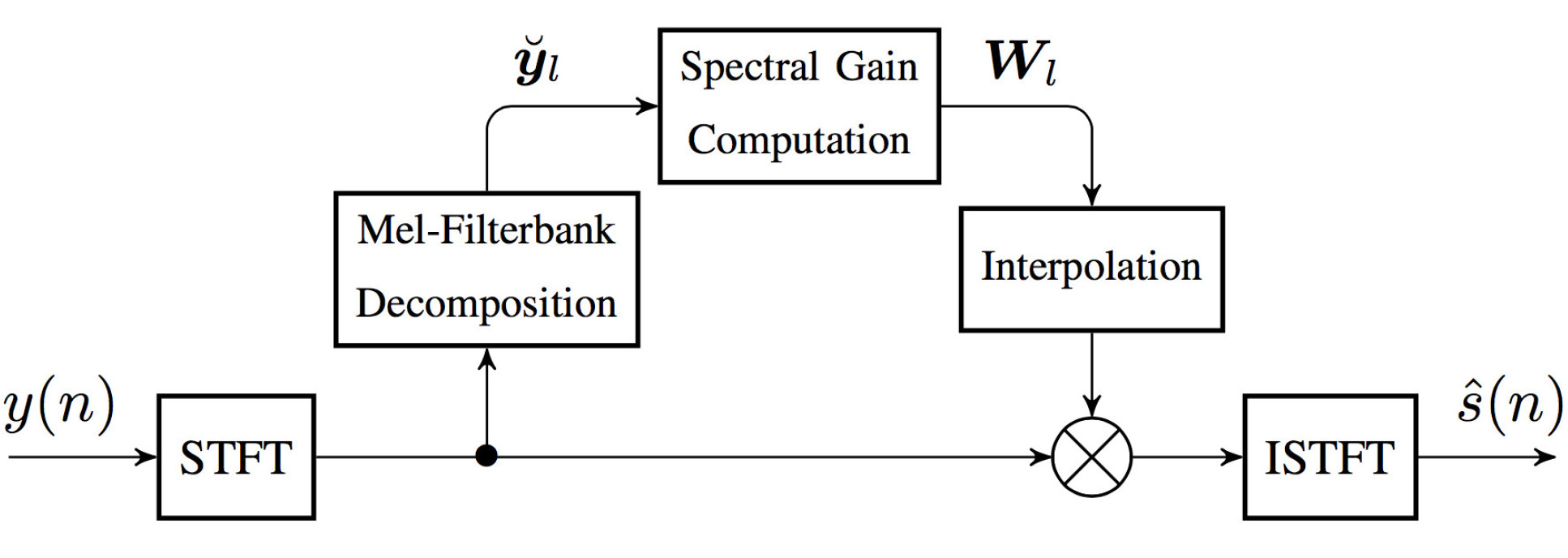
The final aim of the method is to compute a spectral gain Wl to be applied to the degraded speech complex short-time Fourier transform (STFT) coefficients as in spectral enhancement. The estimation of the mean powers needed to compute this gain is formulated as a Bayesian filtering problem on a Mel-frequency scale that jointly estimates them along with the parameters of the acoustic channel. The latter is modelled using a non-negative autoregressive process of order 1 parameterised by T60 and DRR. The clean speech log-power is modelled by a Hidden Markov Model (HMM) in which each state captures the spectral characteristics of a possible prior distribution of the multivariate speech log-power. At each time frame, each one of these possible clean speech prior distributions is tested through a Kalman filter-like update. The one leading to the highest likelihood for the observed power is kept, so as to obtain a posteriori estimates of the speech, reverberation and noise mean powers.
Results from this project are presented in the references below. Please contact mike.brookes@imperial.ac.uk for access to the experimental data in [3]. An implementation in MATLAB of the proposed method is available as spendred.m in the VOICEBOX toolbox.
References
[1] C. S. J. Doire. Single-channel Enhancement of Speech Corrupted by Reverberation and Noise. PhD thesis, Imperial College London, 2016.
[2] C. S. J. Doire, D. M. Brookes, P. A. Naylor, D. Betts, C. M. Hicks, M. A. Dmour, and S. H. Jensen. Single-channel blind estimation of reverberation parameters. In Proc. IEEE Intl Conf. Acoustics, Speech and Signal Processing, Brisbane, Apr. 2015. doi: 10.1109/ICASSP.2015.7177926.
[3] C. S. J. Doire, D. M. Brookes, P. A. Naylor, C. M. Hicks, D. Betts, M. A. Dmour, and S. H. Jensen. Single-channel online enhancement of speech corrupted by reverberation and noise. IEEE Trans. Audio, Speech, Language Processing, Vol. 25, Issue 3, pp.572-587, Mar. 2017. doi: 10.1109/TASLP.2016.2641904.