Randomly Connected Neural Network for Self-Supervised Monocular Depth Estimation
A Hamlyn research team that introduced a novel deep learning method has won the Outstanding Paper Award at AECAI-CARE-OR2.0 workshop in MICCAI 2021.
In computing vision, depth estimation is one of the fundamental problems in terms of predicting the distance of each point in a captured scene relative to the camera. Depth is essential in a divergent range of applications including robotic vision, surgical navigation and mixed reality.
Recently, deep learning models have become very attractive in the depth perception workflow as they provide end-to-end solutions for depth and disparity estimation. In monocular depth estimation, most self-supervised methods adopt the U-Net-based encoder-decoder architecture DispNet, which generates a high-resolution photometric output.
Lead author of this award paper Sam Tukra said: "typically a U-Net model architecture is always used for self-supervised depth estimation. However this architecture may be suboptimal since other studies (that focused on replacing methods) have shown, replacing the encoder part of U-Net with more complex architectures improves results. Typically these improvements come due to the innovative ways the network is wired."
Novel Randomly Connected Neural Networks for Self-Supervised Monocular Depth Estimation
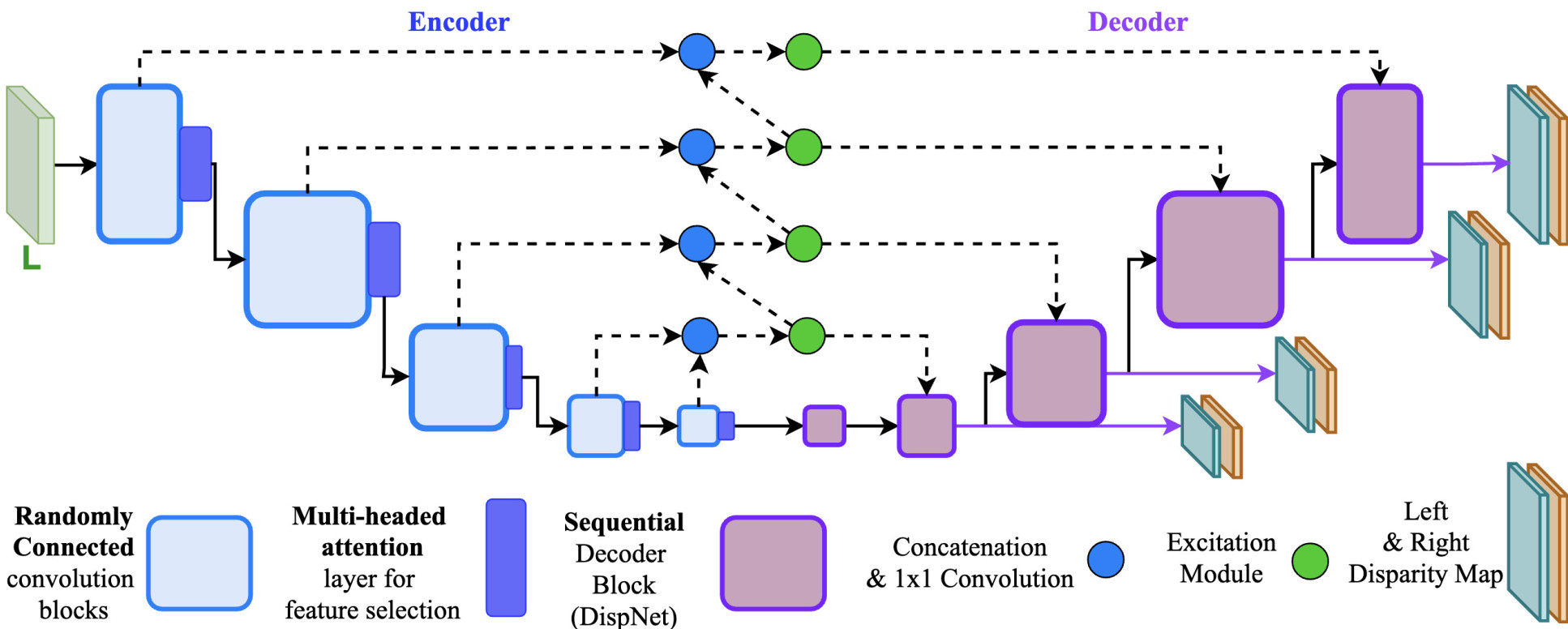
In the light of this, our research team at the Hamlyn Centre proposed a novel randomly connected encoder-decoder architecture for self-supervised monocular depth estimation.
"In order to improve depth estimation we simply challenged the notion I mentioned above by experimenting with randomly connecting neural networks (i.e. no limitation in how these networks are wired). This way we can attain a unique powerful architectures for the specific task (i.e. depth estimation in surgery)" Sam Tukra said.
Inspired by graph theory, our researchers created randomly connected neural networks by modelling them as graphs, where each node is essentially a convolution layer.
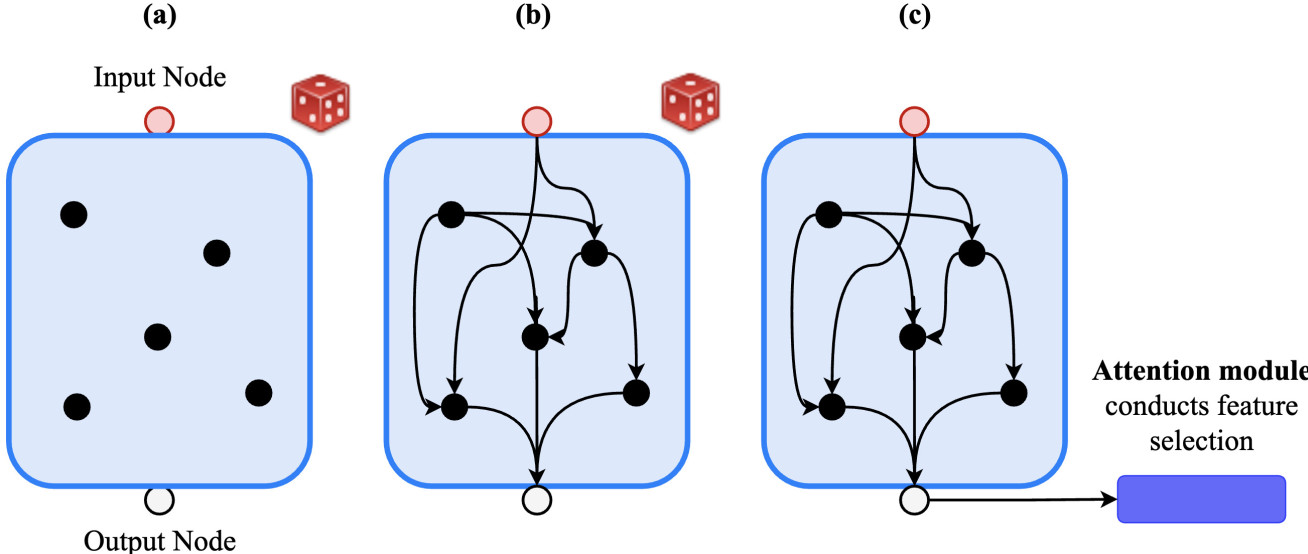
Our researchers simply connected these nodes by using a random graph generator algorithm. Once the graph is created, they converted them into a neural network in a deep learning library (i.e. PyTorch).
To enable efficient search in the connection space, the ‘cascaded random search’ approach is introduced for the generation of random network architectures.
Moreover, our researchers also introduced a new variant of the U-Net topology to improve the expressive power of skip connection feature maps, both spatially and semantically.
"We hope that the proposed methodology guides researchers in understanding how to improve monocular depth estimation without reliance on capturing arduous ground truth." Sam Tukra
Unlike standard U-Net, this new concept included convolution (learnable layers) in the skip connections itself. Our researchers therefore can improve the usage of deep semantic features in the encoder feature maps, which are usually stored in the channels space but not explicitly used.
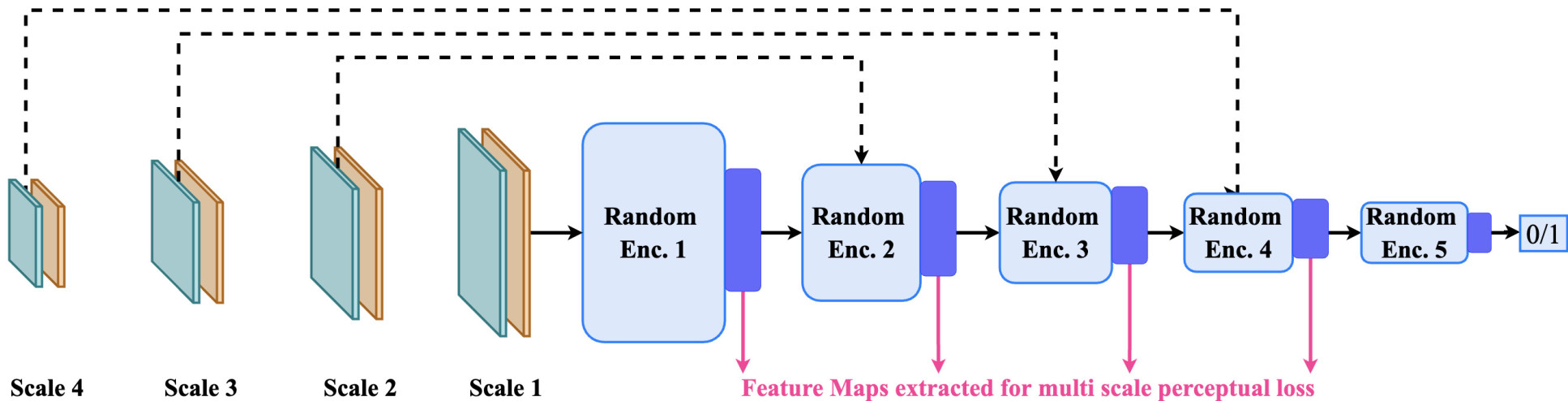
Last but not least, as our researchers realised that multi-scale loss functions are vital for improvement in image reconstruction, they created a new loss function to improve on the image reconstruction quality.
The new loss function efficiently extends deep feature adversarial and perceptual loss to multiple scales for high fidelity view synthesis and error calculation.
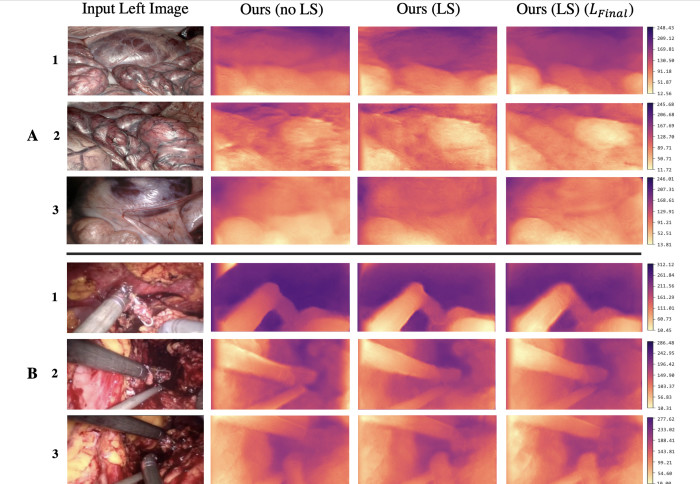
Our research team conducted performance evaluation on two surgical datasets, including comparisons to state-of-the-art self-supervised depth estimation methods.
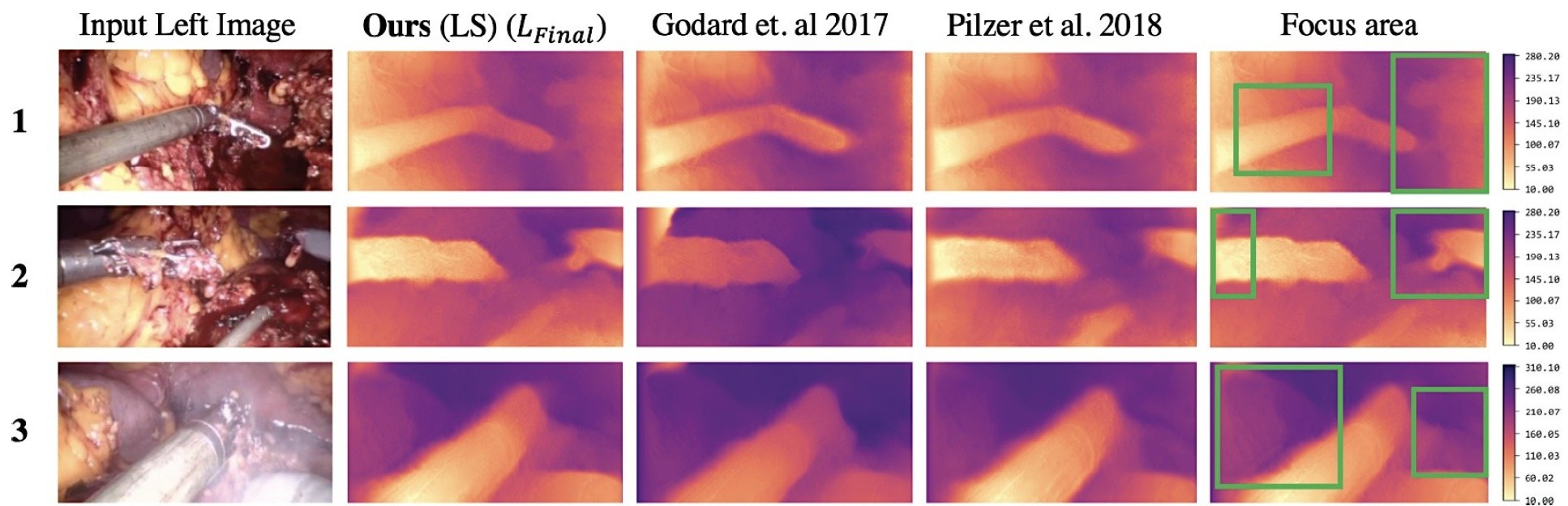
In conclusion, the research results verify that even a randomly connected network with standard convolution operations but innovative inter-connections can learn the task well. Additionally, this research also showed that multi-scale penalty in loss functions is vital for generating finer details.
Our researchers believe that this study will aid in further research when it comes to neural network architecture design. it might also be helpful for those studies that aim to shift from the standard U-Net as well as manual trial and error based approaches to more automated design methods.
Samyakh Tukra and Stamatia Giannarou, "Randomly connected neural networks for self-supervised monocular depth estimation", Computer Methods in Biomechanics and Biomedical Engineering: Imaging & Visualization, November 2021.
Article supporters
Article text (excluding photos or graphics) © Imperial College London.
Photos and graphics subject to third party copyright used with permission or © Imperial College London.
Reporter
Erh-Ya (Asa) Tsui
Enterprise