‘Data Learning’: A new field to help produce more accurate predictive models
by Gemma Ralton

Researchers have proposed a new field called ‘data learning’, integrating machine learning and data assimilation for more accurate modelling.
Academics from Imperial’s Data Science Institute in collaboration with several others from across the college have proposed a new field called ‘Data Learning’, which combines data assimilation and machine learning to help overcome uncertainties in existing predictive models.
Data assimilation (DA) is the approximation of the true state of a physical system by combing observations with a dynamic computer model. DA incorporates observational data into a predictive model to improve forecasted results. However, its approaches are incapable of fully overcoming their assumptions such as nonlinearity.
Similarly, machine learning (ML) shows great capabilities in approximating nonlinear systems and extracting meaningful features from high dimensional data. Yet, in most of the real-world applications, data are noisy, often there is not a ground truth, and there are errors propagating through the ML models to the predictions they generate.
In data assimilation, the errors in the data and models are estimated, weighted, and considered at all times. Therefore, the team proposes the integration of machine learning with data assimilation to increase the reliability of predictions and ultimately make computer models more accurate. This integration they call ‘data learning’.
Uncertainty in numerical models
All numerical models can create uncertainty through the selection of different scales and parameters or through a number of other ways such as linearization, finite precision and rounding errors.
Although machine learning algorithms are capable of assisting or replacing traditional forecasting methods, the training data required for machine learning include numerical approximation and round off errors.
Machine learning models can also pose additional difficulties in real-world scenarios due to dimensionality constraints where datasets become so large they are difficult to work with or, due to the presence of noisy or low quality data.
A new field: Data Learning
To improve the efficiency and accuracy of numerical simulations, the team at Imperial introduce the new field of ‘data learning’ which integrates methods from both data assimilation and machine learning.
This increases the reliability of prediction and reduces error by including information with a physical meaning from observed data.
The resulting cohesion produces a collection of faster and more accurate predictive models, based on the idea that machine learning can be used to learn the past experiences of a data assimilation process.
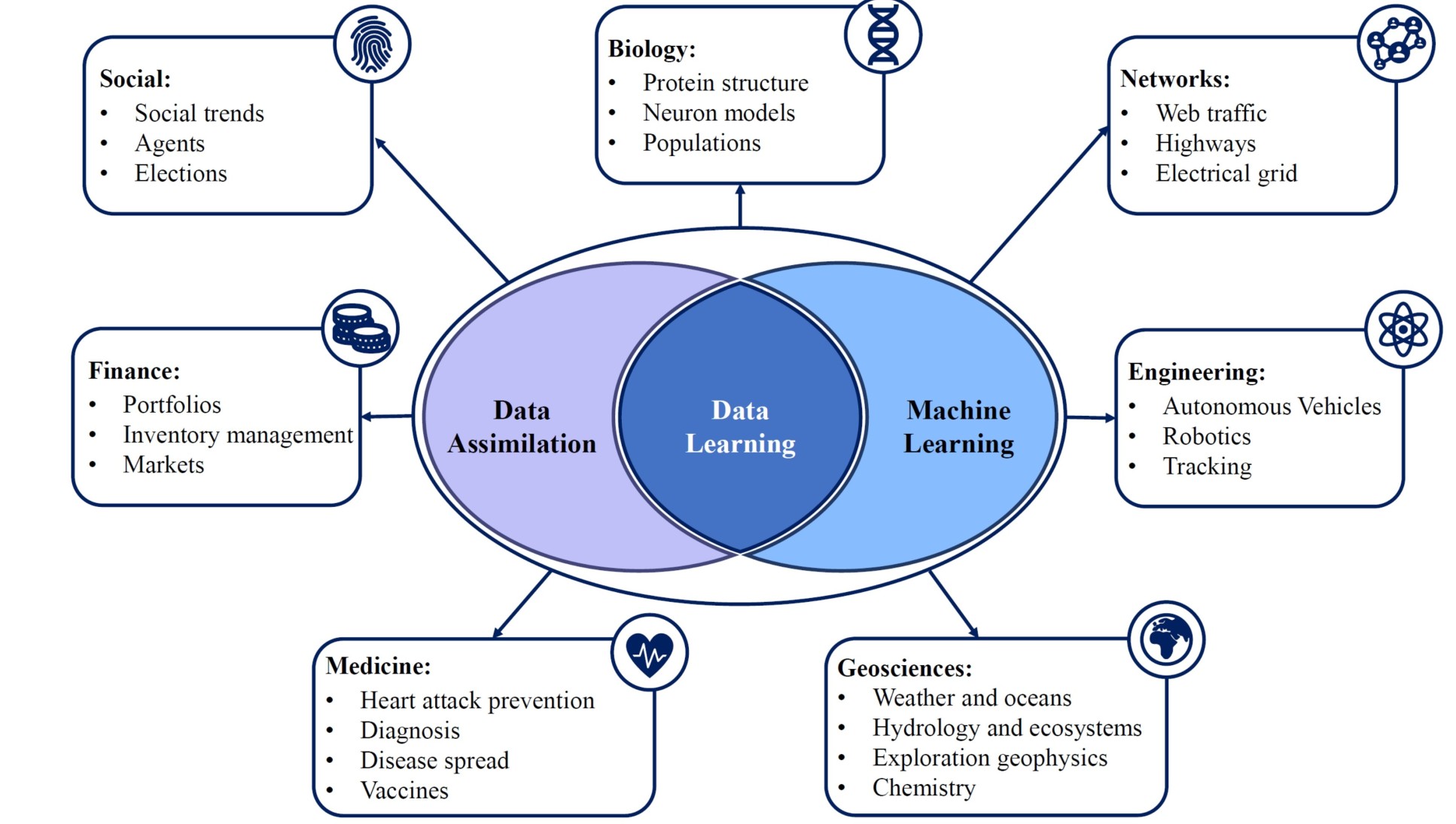
The DataLearning group at Imperial is an interdisciplinary group developing pioneering research on fundamental data assimilation and machine learning for real-world applications.
The group uses digital twins and data assimilation to model real-world observations, with machine learning used to increase the reliability of predictions made by forecasting models.
Data learning can be applied to any field where observations and models co-exist and therefore has applications across social sciences, finance, medicine, engineering and life sciences to name just a few. The group's work has applications including urban air pollution, medical image segmentation, fluid dynamics and wildfire prediction.
Find out more by visiting our Data Learning Research Page or by reading their recently published study: ‘Data Learning: Integrating Data Assimilation and Machine Learning’ by Buizza et al., published on 19 February 2022 in Journal of Computational Science.
Article text (excluding photos or graphics) © Imperial College London.
Photos and graphics subject to third party copyright used with permission or © Imperial College London.
Reporter
Gemma Ralton
Faculty of Engineering