Our vision is to leverage and combine key emerging technologies in Artificial Intelligence (AI) and Engineering Biology (EB) to enable and pioneer a new era of world-leading advances that will directly contribute to the objectives of the National EB Programme.
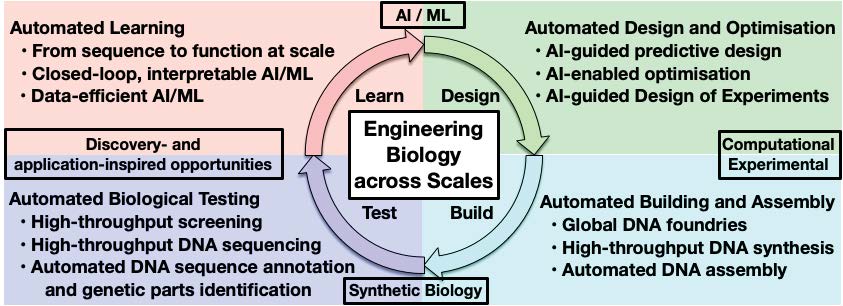
Realising the benefits of EB technologies is predicated on increasing our capability for predictive design and optimisation of engineered biosystems across different EB scales. This will significantly accelerate translation of research and innovation into applications of wide commercial and societal impact. Consequently, AI-4-EB will provide the necessary step-change for the analysis of large, heterogeneous biological data sets and for AI-based design and optimisation of biological systems.
AI-4-EB Exemplar Projects Model © Prof Guy-Bart Stan
AI-4-EB Consortium Projects
The AI-4-EB Consortium supports leading-light projects that tackle different aspects of the Artificial Intelligence and Engineering Biology integration, with a focus on AI development for biological systems and integration of advanced automation technologies.
To enable the efficient engineering of biology for real-world applications, it is necessary to:
- develop new AI methods that allow us to learn across different biological scales, from genotypic
information (DNA/RNA sequences) and phenotypic behaviours (P1); - rewiring regulatory and metabolic networks (P2);
- control intricate interactions between cells for emergent properties (P3);
- design and control interacting cellular communities (P4).
These exemplar projects are augmented by additional projects awarded through the flexibly funded sandpits and community building workshops.
One of the key priorities of the AI-4-EB Consortium is to build a network of inter-connected, inter-disciplinary researchers to develop and apply next-generation AI technologies to EB problems. To achieve this, the consortium has hosted a series of meetings and sandpits to generate novel ideas and new collaborations on AI approaches for real-world use that have been supported by flexible seed funding from the consortium.
There are currently three flexible sandpit projects:
-
FSP1- Mind the Gap: AI-Augmented Cell-Free Systems for In-Cell Predictions
- FSP2 – Developing tools to study single cell heterogeneity
-
FSP3 – Artificial Metabolic Networks
The intersection of Engineering Biology, Big Data, and AI, together with advanced automation engineering, raises many opportunities, but also important questions. For instance: What are the underlying assumptions regarding the ethics and intentions for perceived applications? What kinds of AI-enabled biofutures are anticipated, who is involved, and what might be the ethical concerns associated with some applications?
The AI-4-EB Consortium is therefore developing a Responsible Research and Innovation strategy to address the complex issues arising at the confluence of these two critical transformative technologies.
Moreover, the London Biofoundry which provides state-of-the-art integrated platforms and workflows for the high-throughput synthesis and assembly of DNA constructs is supporting the light leading and flexibly funded projects in the AI-4-EB Consortium.
Light Leading Projects
- P1- Context-Aware Engineering
- P2 – Network Engineering
- P3 – Robust Pattern Engineering
- P4 – Cell Consortium Engineering
[Project Team: Zehui Li, William Beardall, Tobias Cook, Akashaditya Das, Francesca Ceroni, Karen Polizzi, Aaron Zhao, Guy-Bart Stan]
Deep learning methods are universal function approximator, which can easily model underlying patterns in different sequences, including text, image, and biological entities. This project designs advanced deep learning methods to model the genomic sequences.
This project is structured around two primary objectives. Firstly, this project aims to predict transcriptions in mammalian cells using genomic neural networks. It involves capturing dependencies between regulatory elements with transformers, and modelling underlying conditions contributing in gene expressions. The second objective is to develop generative models, which generate promoters sequences to control the expression level of gene expression and bioproduction.
Simultaneously, this project explores the use of Graph Neural Networks (GNNs) in model graph data. Graphs are ubiquitous in biological systems: graphs with different sizes are manifest in common biologicals entities such as proteins, cells, and tissues. Graphs neural networks are effective machine learning models to model graph data. Here, we not only improve upon existing GNNs, but design novel GNNs to capture complex graphs.
Finally, wet-lab experiments will be used to verify the feasibility of the computational models and generate the data to iteratively optimise the performance of these models.
[Project Team: Lun Ai, Stephen Muggleton, Geoff Baldwin]
Exemplar Project 2 has focused on developing AI methods to address the high complexity of navigating and learning host metabolic systems for their optimisation as production platforms. It was previously demonstrated that abductive learning could be used to learn metabolic networks faster and at less cost than random experiments.
This demonstration was based on a subset of 37 genes in aromatic amino acid metabolism. We have developed a new logical framework which expands on this approach to include all 1515 genes included in the most complete E. coli genome-scale metabolic model (iML1515).
Empowered by abductive logical reasoning and active learning together with CRISPRi technology, our framework efficiently and economically validates theoretical simulations for better predictability of host behaviour which will enhance the sustainability of bio-based manufacturing.
Uncovering biology’s robustness principles through AI-engineered Turing patterns
[Project Team: Robert Endres, Mark Isalan, Roozbeh Pazuki, Jure Tica]
From a zebra's stripes to the digits forming in a growing hand, repeat patterns are abundant in biological systems – but how these can be explained mechanistically remains elusive. Seminal work by Alan Turing (1952) proposed one route to the formation of biological structures via a diffusion-driven instability in a reaction-diffusion system. However, this mechanism is fragile and not directly connected to biology, with its myriad molecules and complex signalling pathways. Due to the immensely large high-dimensional parameter space of models, ‘Turing islands’ are notoriously difficult to find in parameter space. However, deep learning is highly suitable for solving this “inverse” problem with sparse data.
In Objective 1, we aim to design robust synthetic Turing networks in growing bacterial colonies, aided by a mathematical model of partial differential equations. In Objective 2, to infer model parameters of high-dimensional models from patterns, we solve the inverse problem via physics-informed deep learning. In the future, this will enable the engineering of gene circuits at the "community design" level, enabling next-generation engineered microbial consortia with self-organising properties, with numerous applications in nanotechnology, self-assembly, and tissue engineering.
Project Team: [Pedro Fontanarrosa, Guy-Bart Stan, Marc Deisenroth, Chris Barnes]
Building synthetic microbial communities allows us to create distributed systems that mitigate bottlenecks encountered when engineering single strains, especially as functional complexity increases. However, creating stable and resiliant communities is the main obstacle to their widespread adoption.
Previous work has used mechanistic modelling and deep learning to design desired target behaviours. However, mechanistic modelling is computationally demanding, rendering it useless on large communities.Deep learning approaches are able to tackle bigger problems, but the connections in the fitted networks do not correspond to biological entities and the corresponding biological network structures must be inferred post-hoc. We will tackle this using Gaussian processes (GP), which strike a balance between capturing complex behaviours and being directly interpretable.
We will develop a new approach to community design and predict interactions that lead to stable communities. These will be tested using engineered E. coli strains and measurement workflows in the London Biofoundry.
Flexibly Funded Sandpit Projects
- FSP1 - Mind the Gap: AI-Augmented Cell-Free Systems for In-Cell Predictions
- FSP2 – Developing tools to study single cell heterogeneity
- FSP3 – Artificial Metabolic Networks
Project Team: [Lucia Marucci, Natalio Krasnogor, Claire Grierson, Paul Freemont, Guy-Bart Stan, Marko Storch, Harrison Steel, Matthew Haines]
For effective use of AI, suitable software, hardware and plentiful data are required. Currently, there are many software options for “learning” or “modelling” biodata, and hardware capabilities (e.g., national biofoundries) are becoming more accessible.
Engineering Biology (EB) suffers, however, from a lack of curated datasets through which the community could effectively learn to use AI/ML methods. This project tackles a data gap that could help accelerate Design Build Test Learn (DBTL) cycles in EB.
Specifically, we seek to curate a high-quality dataset that matches expression of a given product pathway in cell-free extracts to its expression in-vivo. Machine Learning (ML) algorithms will be used to “bridge the gap” between TX/TL outputs and their in-vivo counterparts, while in parallel we will investigate how these ML approaches can map simulations of the most complete mathematical representations of a living cell (i.e. whole-cell models) to in vivo experimental results.
Project Team: [Cinzia Klemm, Kiyan Shabestary, Marko Storch, Diego Oyarzun, Guy-Bart Stan, Paul Freemont, Rodrigo Ledesma Amaro]
Technologies with single cell resolution are revolutionising how we understand and exploit microbial cells and communities. Methods like high-throughput microfluidic-based microscopy and scRNAseq provide us with a wealth of data that can be used to quantify cell-to-cell heterogeneity, phenotypic subpopulations, cellular dynamics and interactions. However, data analysis of these powerful technologies and their combination is still in their infancy and AI is well placed to unravel the full potential of this field.
This project aims to develop a cutting-edge, in-house capability for high-throughput single cell analysis at the London Biofoundry that can support projects with academics and companies.
The immediate applications of this project are in the space of microbial foods, working with S. cerevisiae or baker yeast, to understand how the single cell variability in this organism can affect food manufacturing and the future of designed microbial foods.
Project Team: [Shishun Liang, Patrick Jones, Jean-Loup Faulon, Geoff Baldwin]
The Sandpit Project aims to leverage the capabilities of multi-functional library screening strategies with an AI model. The Artificial Metabolic Network (AMN) model integrates a neural net with a genome-scale metabolic model that can be trained against media conditions and gene knockouts. This will be used to improve predictions that enable optimisation of the production of violacein from the essential host metabolite tryptophan via a heterologous pathway.
These library screening strategies serve as powerful, high-throughput methods for systematically investigating gene perturbations within host cell systems. In collaboration with Inscripta, we have constructed a genome-scale promoter substitution library, as well as a new dual-gRNA CRISPRi library for prokaryotic cells. The previous AMN work utilized low throughput cell growth assays for model training. Our objective is to refine the AMN model's training method workflow to enhance its capacity for processing high throughput data and yield a robust model to deal with multi-functional gene perturbation.
Our efforts in merging the potency of library screening strategies with the predictive capacity of the AMN model are directed towards surmounting current constraints in developing efficient, optimized engineering methods for host chassis. The promise of predictive engineering in cellular hosts through advanced machine learning holds a radical potential to transform our ability to shift towards a bio-based economy.
Crosscutting Projects
The London Biofoundry based at the iHub at Imperial's White City campus is supporting the light leading and flexibly funded projects in the AI-4-EB Consortium.
The Responsible Research and Innovation (RRI) component of the AI4EB project is undertaking research to probe the societal, responsibility, and ethical implications arising from the confluence of the two transformative technologies of engineering biology (EB) and artificial intelligence (AI).
The RRI team is pursuing an approach that encompasses anticipation of technological and innovation developments at the intersection of EB and AI, reflection on their implications, and engagement and interaction with researchers and stakeholders internal and external to the project.
Given limited project resources for RRI, and through engagement with AI4EB leadership and researchers, the RRI team has targeted three specific key research questions:
- What are the ethical and RRI implications of AI4EB in the lab?
- What are the ethical and RRI implications of the outcomes of AI4EB as they are generalized in the economy and society? (i.e., outside the lab); and
- How can and should these implications be addressed?
Contact us

For more information about the
AI-4-EB Consortium, contact
Dr Gifty Tetteh
Research Consortium Manager
Department of Bioengineering
Imperial College London