
Towards a Uniform Evaluation Methodology
Benchmark Suite
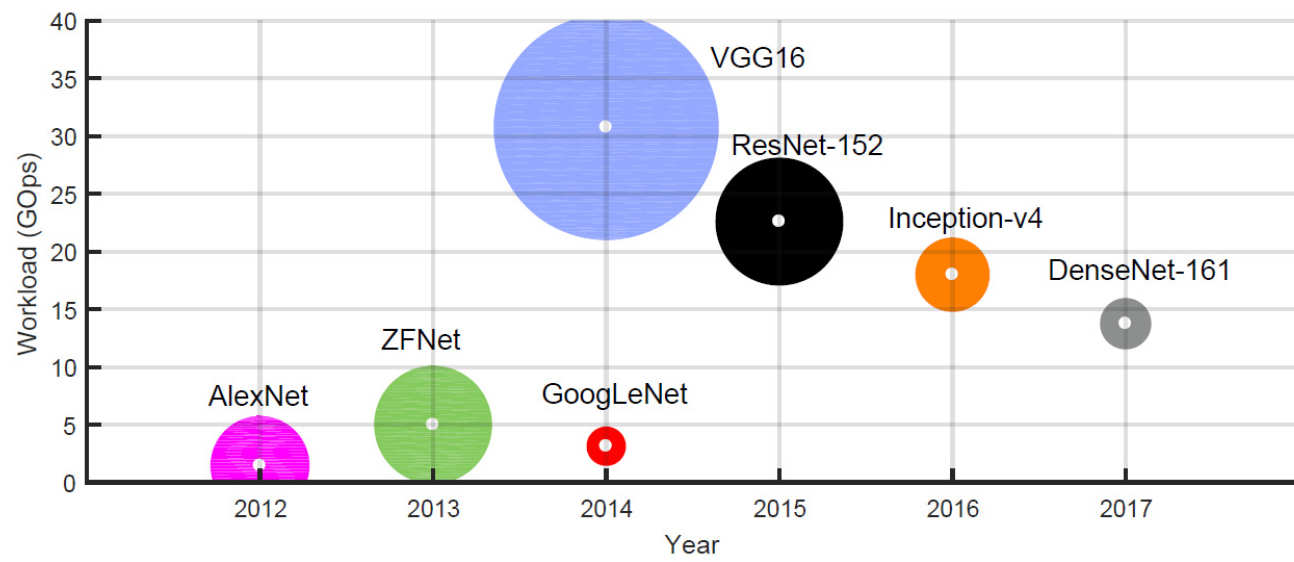 The proposed benchmark suite includes CNNs that are widely used and whose accuracy has been extensively studied by the deep learning community. Each CNN poses a unique hardware mapping challenge and stresses the FPGA toolflow from a different aspect. The main challenges to be addressed include CNNs that are (1) computation bounded, (2) off-chip memory bandwidth bounded, (3) on-chip memory capacity bounded, (4) with high layer dependency and (5) irregular and sparse layer connectivity that challenges scheduling.
The proposed benchmark suite includes CNNs that are widely used and whose accuracy has been extensively studied by the deep learning community. Each CNN poses a unique hardware mapping challenge and stresses the FPGA toolflow from a different aspect. The main challenges to be addressed include CNNs that are (1) computation bounded, (2) off-chip memory bandwidth bounded, (3) on-chip memory capacity bounded, (4) with high layer dependency and (5) irregular and sparse layer connectivity that challenges scheduling.
Our proposed comprehensive benchmark suite consists of the following CNN models:
| Model | Depth | Design Principles | Challenges | Download |
|---|---|---|---|---|
| Alexnet 2012 [1] | 8 |
|
|
alexnet.prototxt |
| ZFNet 2013 [2] | 8 |
|
|
zfnet.prototxt |
| VGG16 2014 [3] | 16 |
|
|
vgg16.prototxt |
| GoogLeNet 2014 [4] | 22 |
|
|
googlenet.prototxt |
| ResNet-152 2015 [5] | 152 |
|
|
resnet152.prototxt |
| Inception-v4 2016 [6] | 72 |
|
|
inception_v4.prototxt |
| DenseNet-161 2017 [7] | 161 |
|
|
densenet161.prototxt |
Evaluation Metrics
For a complete charactrisation of the hardware design points generated by each toolflow and a fair comparison across different FPGA platforms, the performance of the system should be reported using metrics that capture the following essential attributes:
- Throughput: is the primamary performance metric of interest in applications such as image recognition and large-scale, multi-user analytics services over large amounts of data. Throughput is measured in GOp/s and is often achieved by processing large batches of inputs.
- Latency: becomes the primary critical factor in applications such as self-driving cars and autonomous systems, but also in particular real-time cloud-based services. Measured in seconds, latency is the time between when an input enters the computing system and when the output is produced. In such scenarios, batch processing adds a prohibitive latency overhead and is often not an option.
- Resource Consumption: is an indicator of the efficiency of the utilisation of the available resources on the target platform by the designs generated by a toolflow, including the DSPs, on-chip RAM, logic and FFs.
- Application-Level Accuracy: is a crucial metric when approximation techniques are employed by a toolflow for the efficient mapping of CNNs. Such techniques may include precision optimisation or lossy compression methods and can have an impact on the application-level accuracy of the CNN. Potential performance-accuracy trade-offs have to be quantified and reported in terms of accuracy degradation.
Reporting all these criteria play an important role in determining the strategic trade-offs made by a toolflow. To measure the quality of a CNN-to-FPGA toolflow, we propose the following methodology:
- Throughput in GOp/s with explicitly specified GOp/network, amount of weights and batch sizes, and latency in seconds/input with batch size of 1, in order to present the throughput-latency relationship, should be included in the evaluation reports.
- Resource-normalised metrics are meaningful when comparing designs that target devices from the same FPGA family optimised for the same application domain. In this scenario, performance normalised with respect to logic and DSPs would allow the comparison of hardware designs for the same network on FPGAs of the same family.
- Power-normalised throughput and latency should also be reported for comparison with other parallel architectures such as CPUs, GPUs and DSPs.
- Since resource-normalised performance does not capture the effect of off- and on-chip memory bandwidth and capacity despite being critical for achieving high performance, target FPGA platform details should be included that explicitly indicate the off- and on-chip memory specifications.
- All measurements should be made for various CNNs, with emphasis on the proposed benchmark suite of the previous section, in order to demonstrate the quality of results subject to the different mapping challenges posed by each benchmark model.
Citation
Please cite the following paper if you find this benchmarking suite useful for your work:
Venieris, S.I., Kouris, A. and Bouganis, C.S., 2018. Toolflows for Mapping Convolutional Neural Networks on FPGAs: A Survey and Future Directions. arXiv preprint arXiv:1803.05900.
References
[1] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. 2012. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems.
[2] Matthew D. Zeiler and Rob Fergus. 2014. Visualizing and Understanding Convolutional Networks. In ECCV.
[3] K. Simonyan and A. Zisserman. 2015. Very Deep Convolutional Networks for Large-Scale Image Recognition. In International Conference on Learning Representations (ICLR).
[4] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. 2015. Going Deeper with Convolutions. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[5] K. He, X. Zhang, S. Ren, and J. Sun. 2016. Deep Residual Learning for Image Recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
[6] Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, and Alexander Alemi. 2017. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In AAAI Conference on Artificial Intelligence.
[7] Gao Huang, Zhuang Liu, Laurens van der Maaten, and Kilian Q Weinberger. 2017. Densely Connected Convolutional Networks. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)





















































