
Computational Machine Learning
Our vision is to bring Machine Learning algorithms closer to every–day life, enabling as such humans and robots to perform their tasks in a most efficient way. Towards this vision, our aim is to design systems that are able to apply knowledge that have been programmed with on the field (inference stage), but also to design systems that are able to acquire new knowledge as it becomes available (training stage) being able as such to adapt to environment and handle previously unseen inputs.
As such, our group performs research on mapping Machine Learning algorithms into digital hardware aiming at high performance (embedded) systems with reduced power consumption. Our work takes a holistic approach to the problems, by coupling the design of the machine learning algorithm with the design of the hardware systems. By exposing the hardware characteristics to the design of the Machine Algorithm, and vice versa, significant gains in performance and power consumption are obtained, making Machine Learning and AI deployable to real-life scenarios.
HARFLOW3D:
A Latency-Oriented 3D-CNN Accelerator Toolflow for HAR on FPGA Devices
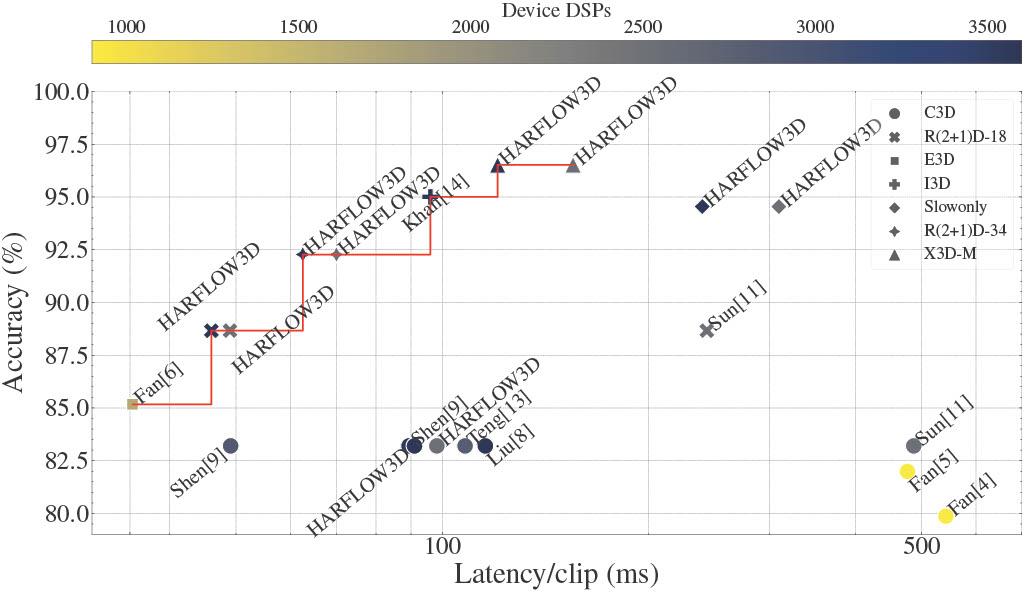 For Human Action Recognition tasks (HAR), 3D Convolutional Neural Networks have proven to be highly effective, achieving state-of-the-art results. This study introduces a novel streaming architecture-based toolflow for mapping such models onto FPGAs considering the model’s inherent characteristics and the features of the targeted FPGA device. The HARFLOW3D toolflow takes as input a 3D CNN in ONNX format and a description of the FPGA characteristics, generating a design that minimises the latency of the computation. The toolflow is comprised of a number of parts, including (i) a 3D CNN parser, (ii) a performance and resource model, (iii) a scheduling algorithm for executing 3D models on the generated hardware, (iv) a resource-aware optimisation engine tailored for 3D models, (v) an automated mapping to synthesizable code for FPGAs. The ability of the toolflow to support a broad range of models and devices is shown through a number of experiments on various 3D CNN and FPGA system pairs. Furthermore, the toolflow has produced high-performing results for 3D CNN models that have not been mapped to FPGAs before, demonstrating the potential of FPGA-based systems in this space. Overall, HARFLOW3D has demonstrated its ability to deliver competitive latency compared to a range of state-of-the-art hand-tuned approaches, being able to achieve up to 5× better performance compared to some of the existing works.
For Human Action Recognition tasks (HAR), 3D Convolutional Neural Networks have proven to be highly effective, achieving state-of-the-art results. This study introduces a novel streaming architecture-based toolflow for mapping such models onto FPGAs considering the model’s inherent characteristics and the features of the targeted FPGA device. The HARFLOW3D toolflow takes as input a 3D CNN in ONNX format and a description of the FPGA characteristics, generating a design that minimises the latency of the computation. The toolflow is comprised of a number of parts, including (i) a 3D CNN parser, (ii) a performance and resource model, (iii) a scheduling algorithm for executing 3D models on the generated hardware, (iv) a resource-aware optimisation engine tailored for 3D models, (v) an automated mapping to synthesizable code for FPGAs. The ability of the toolflow to support a broad range of models and devices is shown through a number of experiments on various 3D CNN and FPGA system pairs. Furthermore, the toolflow has produced high-performing results for 3D CNN models that have not been mapped to FPGAs before, demonstrating the potential of FPGA-based systems in this space. Overall, HARFLOW3D has demonstrated its ability to deliver competitive latency compared to a range of state-of-the-art hand-tuned approaches, being able to achieve up to 5× better performance compared to some of the existing works.
The work has been open-sourced at https://github.com/ICIdsl/harflow3d.
Multi-Precision Policy Enforced Training (MuPPET):
A precision-switching strategy for quantised fixed-point training of CNNs
 Large-scale Convolutional Neural Networks (CNNs) suffer from very long training times, spanning from hours to weeks, limiting the productivity and experimentation of deep learning practitioners. As networks grow in size and complexity, training time can be reduced through low-precision data representations and computations. However, in doing so the final accuracy suffers due to the problem of vanishing gradients. Existing state-of-the-art methods combat this issue by means of a mixed-precision approach utilising two different precision levels,FP32 (32-bit floating-point) and FP16/FP8(16-/8-bit floating-point), leveraging the hardware support of recent GPU architectures for FP16 operations to obtain performance gains. This work pushes the boundary of quantised training by employing a multilevel optimisation approach that utilises multiple precisions including low-precision fixed-point representations. The novel training strategy, MuPPET, combines the use of multiple number representation regimes together with a precision-switching mechanism that decides at run time the transition point between precision regimes. Overall, the proposed strategy tailors the training process to the hardware-level capabilities of the target hardware architecture and yields improvements in training time and energy efficiency compared to state-of-the-art approaches. Applying MuPPET on the training of AlexNet, ResNet18 and GoogLeNet on ImageNet(ILSVRC12) and targeting an NVIDIA Turing GPU, MuPPET achieves the same accuracy as standard full-precision training with training-time speedup of up to 1.84× and an average speedup of 1.58× across the networks.
Large-scale Convolutional Neural Networks (CNNs) suffer from very long training times, spanning from hours to weeks, limiting the productivity and experimentation of deep learning practitioners. As networks grow in size and complexity, training time can be reduced through low-precision data representations and computations. However, in doing so the final accuracy suffers due to the problem of vanishing gradients. Existing state-of-the-art methods combat this issue by means of a mixed-precision approach utilising two different precision levels,FP32 (32-bit floating-point) and FP16/FP8(16-/8-bit floating-point), leveraging the hardware support of recent GPU architectures for FP16 operations to obtain performance gains. This work pushes the boundary of quantised training by employing a multilevel optimisation approach that utilises multiple precisions including low-precision fixed-point representations. The novel training strategy, MuPPET, combines the use of multiple number representation regimes together with a precision-switching mechanism that decides at run time the transition point between precision regimes. Overall, the proposed strategy tailors the training process to the hardware-level capabilities of the target hardware architecture and yields improvements in training time and energy efficiency compared to state-of-the-art approaches. Applying MuPPET on the training of AlexNet, ResNet18 and GoogLeNet on ImageNet(ILSVRC12) and targeting an NVIDIA Turing GPU, MuPPET achieves the same accuracy as standard full-precision training with training-time speedup of up to 1.84× and an average speedup of 1.58× across the networks.
The work has been open-sourced at https://github.com/ICIdsl/muppet
Now that I can see, I can improve: Enabling data-driven finetuning of CNNs on the edge
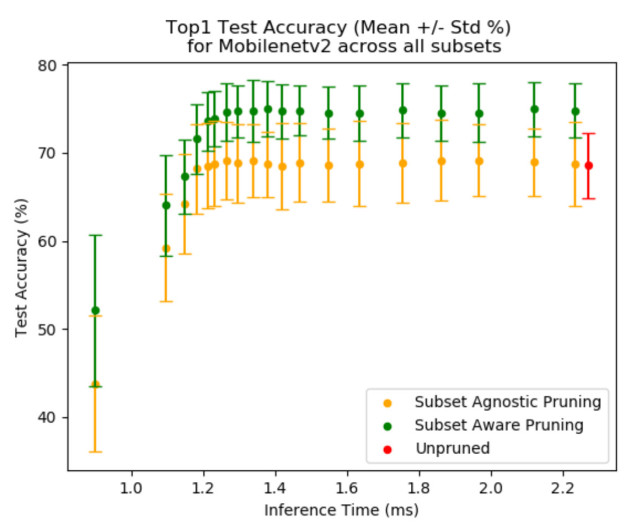 In today’s world, a vast amount of data is being generated by edge devices that can be used as valuable training data to improve the performance of machine learning algorithms in terms of the achieved accuracy or to reduce the compute requirements of the model. However, due to user data privacy concerns as well as storage and communication bandwidth limitations, this data cannot be moved from the device to the data centre for further improvement of the model and subsequent deployment. As such there is a need for increased edge intelligence, where the deployed models can be fine-tuned on the edge, leading to improved accuracy and/or reducing the model’s workload as well as its memory and power footprint. In the case of Convolutional Neural Networks (CNNs), both the weights of the network as well as its topology can be tuned to adapt to the data that it processes. This paper provides a first step towards enabling CNN finetuning on an edge device based on structured pruning. It explores the performance gains and costs of doing so and presents an extensible open-source framework ADaPT that allows the deployment of such approaches on a wide range of network architectures and devices. The results show that on average, data-aware pruning with re-training can provide 10.2pp increased accuracy over a wide range of subsets, networks and pruning levels with a maximum improvement of 42.0pp over pruning and retraining in a manner agnostic to the data being processed by the network.
In today’s world, a vast amount of data is being generated by edge devices that can be used as valuable training data to improve the performance of machine learning algorithms in terms of the achieved accuracy or to reduce the compute requirements of the model. However, due to user data privacy concerns as well as storage and communication bandwidth limitations, this data cannot be moved from the device to the data centre for further improvement of the model and subsequent deployment. As such there is a need for increased edge intelligence, where the deployed models can be fine-tuned on the edge, leading to improved accuracy and/or reducing the model’s workload as well as its memory and power footprint. In the case of Convolutional Neural Networks (CNNs), both the weights of the network as well as its topology can be tuned to adapt to the data that it processes. This paper provides a first step towards enabling CNN finetuning on an edge device based on structured pruning. It explores the performance gains and costs of doing so and presents an extensible open-source framework ADaPT that allows the deployment of such approaches on a wide range of network architectures and devices. The results show that on average, data-aware pruning with re-training can provide 10.2pp increased accuracy over a wide range of subsets, networks and pruning levels with a maximum improvement of 42.0pp over pruning and retraining in a manner agnostic to the data being processed by the network.
This work has been open-sourced at https://github.com/adityarajagopal/pruning
Caffe Barista: Brewing Caffe with FPGAs in the Training Loop
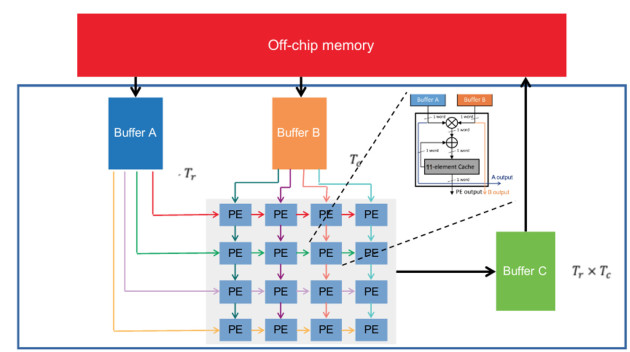 As the complexity of deep learning (DL) models increases, their compute requirements increase accordingly. Deploying a Convolutional Neural Network (CNN) involves two phases: training and inference. With the inference task typically taking place on resource-constrained devices, a lot of research has explored the field of low-power inference on custom hardware accelerators. On the other hand, training is both more compute-and memory-intensive and is primarily performed on power-hungry GPUs in large-scale data centres. CNN training on FPGAs is a nascent field of research. This is primarily due to the lack of tools to easily prototype and deploy various hardware and/or algorithmic techniques for power-efficient CNN training. This work presents Barista, an automated toolflow that provides seamless integration of FPGAs into the training of CNNs within the popular deep learning framework Caffe. To the best of our knowledge, this is the only tool that allows for such versatile and rapid deployment of hardware and algorithms for the FPGA-based training of CNNs, providing the necessary infrastructure for further research and development.
As the complexity of deep learning (DL) models increases, their compute requirements increase accordingly. Deploying a Convolutional Neural Network (CNN) involves two phases: training and inference. With the inference task typically taking place on resource-constrained devices, a lot of research has explored the field of low-power inference on custom hardware accelerators. On the other hand, training is both more compute-and memory-intensive and is primarily performed on power-hungry GPUs in large-scale data centres. CNN training on FPGAs is a nascent field of research. This is primarily due to the lack of tools to easily prototype and deploy various hardware and/or algorithmic techniques for power-efficient CNN training. This work presents Barista, an automated toolflow that provides seamless integration of FPGAs into the training of CNNs within the popular deep learning framework Caffe. To the best of our knowledge, this is the only tool that allows for such versatile and rapid deployment of hardware and algorithms for the FPGA-based training of CNNs, providing the necessary infrastructure for further research and development.
This work has been open-sourced at https://github.com/ICIdsl/caffe_fpga
CascadeCNN: Pushing the performance limits of quantisation in CNNs
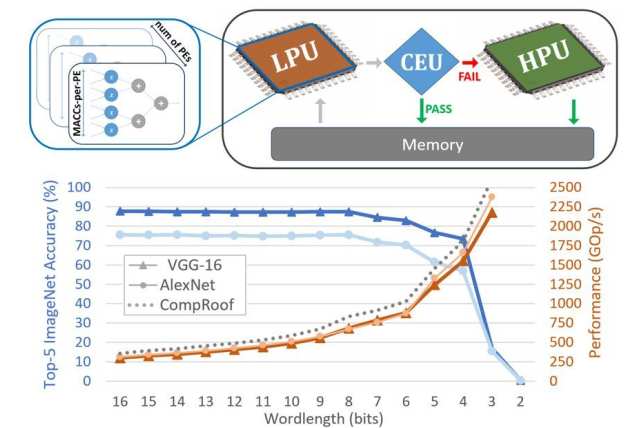 CascadeCNN is an automated toolflow that pushes the quantisation limits of any given CNN model, aiming to perform high-throughput inference by exploiting the computation time-accuracy trade-off. A two-stage architecture tailored for any given CNN-FPGA pair is generated, consisting of a low- and high-precision unit in a cascade. A confidence evaluation unit between them is employed to identify misclassified cases from the excessively low-precision unit and forward them to the high-precision unit for re-processing.
CascadeCNN is an automated toolflow that pushes the quantisation limits of any given CNN model, aiming to perform high-throughput inference by exploiting the computation time-accuracy trade-off. A two-stage architecture tailored for any given CNN-FPGA pair is generated, consisting of a low- and high-precision unit in a cascade. A confidence evaluation unit between them is employed to identify misclassified cases from the excessively low-precision unit and forward them to the high-precision unit for re-processing.
Experiments demonstrate that the proposed toolflow can achieve a performance boost up to 55% for VGG-16 and 48% for AlexNet over the baseline design for the same resource budget and accuracy, without the need of retraining the model or accessing the training data, enabling extreme quantisation in CNNs under privacy-constrained settings.
f-CNNx : Enabling emerging multi-CNN applications
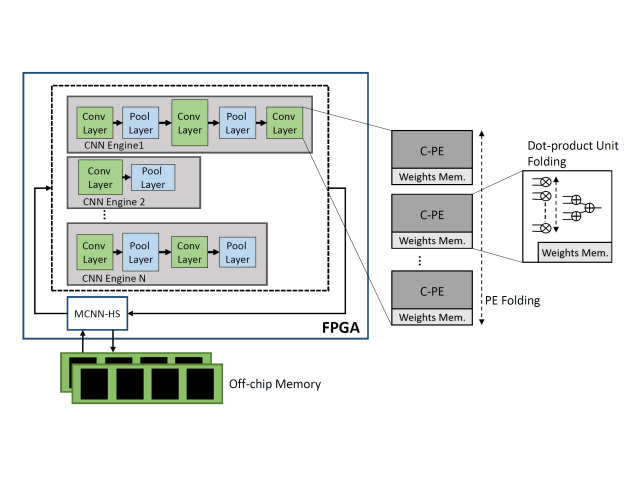 In the construction of complex AI systems, CNN models are used as building blocks of a larger system. In this respect, multi-CNN systems have emerged, employing several models, each one trained for a different subtask. Nevertheless, deploying multiple models on a target platform poses a number of challenges. From a resource allocation perspective, with each model targeting a different task, the performance constraints, such as required throughput and latency, vary accordingly. Instead of being model-agnostic, this property requires the design of an architecture that captures and reflects the performance requirements of each model. Moreover, in resource-constrained setups, multiple CNNs compete for the same pool of resources and hence resource allocation between models becomes a critical factor. f-CNNx is a toolflow which addresses the mapping of multiple CNNs on a target FPGA platform while meeting the required performance for each model. Starting from a set of pretrained models, f-CNNx explores a wide range of resource and bandwidth allocations and incorporates the application-level importance of each model by means of multiobjective cost functions to guide the design space exploration to the optimum hardware design.
In the construction of complex AI systems, CNN models are used as building blocks of a larger system. In this respect, multi-CNN systems have emerged, employing several models, each one trained for a different subtask. Nevertheless, deploying multiple models on a target platform poses a number of challenges. From a resource allocation perspective, with each model targeting a different task, the performance constraints, such as required throughput and latency, vary accordingly. Instead of being model-agnostic, this property requires the design of an architecture that captures and reflects the performance requirements of each model. Moreover, in resource-constrained setups, multiple CNNs compete for the same pool of resources and hence resource allocation between models becomes a critical factor. f-CNNx is a toolflow which addresses the mapping of multiple CNNs on a target FPGA platform while meeting the required performance for each model. Starting from a set of pretrained models, f-CNNx explores a wide range of resource and bandwidth allocations and incorporates the application-level importance of each model by means of multiobjective cost functions to guide the design space exploration to the optimum hardware design.
Landscape of CNN-to-FPGA toolflows and future directions
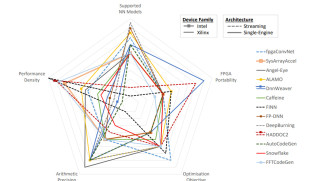
Recently, FPGAs have emerged as a potential platform that can reduce significantly power consumption cost while meeting the compute requirements of modern deep learning systems. In this project, we survey the landscape of toolflows which automate the mapping of the CNN inference stage to FPGA-based platforms. From a deep learning scientist perspective, we conduct a study over the supported deep learning models, including DNNs, CNNs and LSTMs, the achieved processing speed and the applicability of each toolflow on specific deep learning applications, from latency-critical mobile systems to high-throughput cloud services. From a computer engineering perspective, we present a detailed analysis of the architectural choices, design space exploration methods and implementation optimisations of the existing tools, together with insightful discussions. The existing FPGA tooflows have employed ad-hoc evaluation methodologies, by targeting different CNN models and reporting the achieved performance in a non-uniform manner. A uniform evaluation methodology is proposed in order to enable the thorough and comparative evaluation of CNN-to-FPGA toolflows (see more).
With an eye to the future of FPGA-based deep learning, we present a set of promising areas of research that can bridge the gap between FPGAs and deep learning practitioners and enable FPGAs to provide the necessary compute infrastructure that can drive future deep learning algorithmic innovations.
Approximate FPGA-based LSTMs
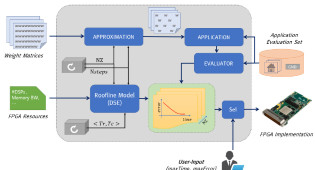 Long Short-Term Memory (LSTM) networks have demonstrated state-of-the-art accuracy in several pattern recognition tasks, with the prominence of Natural Language Processing (NLP) and speech recognition. Nevertheless, as LSTM models increase in complexity and sophistication, so do their computational and memory requirements. Emerging latency-sensitive applications including mobile robots and autonomous vehicles often operate under stringent computation time constraints, where a decision has to be made in real-time. To address this problem, we developed an approximate computing scheme which enables LSTMs to increase their accuracy as a function of the computation time budget, together with an FPGA-based architecture for the high-performance deployment of the approximate LSTMs. By targeting the real-life Neural Image Caption (NIC) model developed by Google, the proposed framework requires 6.65x less time to achieve the same application-level accuracy compared to a baseline implementation, while achieving an average of 25x higher accuracy under the same computation time constraints. This is the first work in the literature to address the deployment of LSTMs under computation time constraints.
Long Short-Term Memory (LSTM) networks have demonstrated state-of-the-art accuracy in several pattern recognition tasks, with the prominence of Natural Language Processing (NLP) and speech recognition. Nevertheless, as LSTM models increase in complexity and sophistication, so do their computational and memory requirements. Emerging latency-sensitive applications including mobile robots and autonomous vehicles often operate under stringent computation time constraints, where a decision has to be made in real-time. To address this problem, we developed an approximate computing scheme which enables LSTMs to increase their accuracy as a function of the computation time budget, together with an FPGA-based architecture for the high-performance deployment of the approximate LSTMs. By targeting the real-life Neural Image Caption (NIC) model developed by Google, the proposed framework requires 6.65x less time to achieve the same application-level accuracy compared to a baseline implementation, while achieving an average of 25x higher accuracy under the same computation time constraints. This is the first work in the literature to address the deployment of LSTMs under computation time constraints.
Latency-Driven Design for FPGA-based CNNs
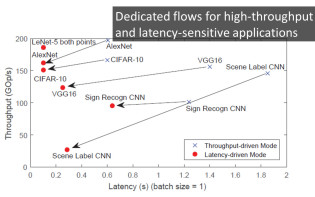
The majority of existing CNN implementations, targeting CPUs, GPUs and FPGAs, are optimised with high throughput as the primary objective. Emerging new AI systems, from self-driving cars and UAVs to low response-time, cloud-based analytics services, require the very low-latency execution of several CNN-based tasks without the processing of inputs in batches. To meet these requirements, we place latency at the centre of optimisation and generate latency-optimised hardware designs for the target CNN-FPGA pairs. This is achieved by introducing a latency-driven methodology, which enables the high-performance execution of CNNs without the need for batch processing. The developed approach enables the expansion of the architectural design space, to meet the performance needs of modern latency-sensitive applications and delivers up to 73.54x and 5.61x latency improvements over throughput-optimised designs on AlexNet and VGG-16 respectively.
fpgaConvNet: a framework for mapping Convolutional Neural Networks on FPGAs
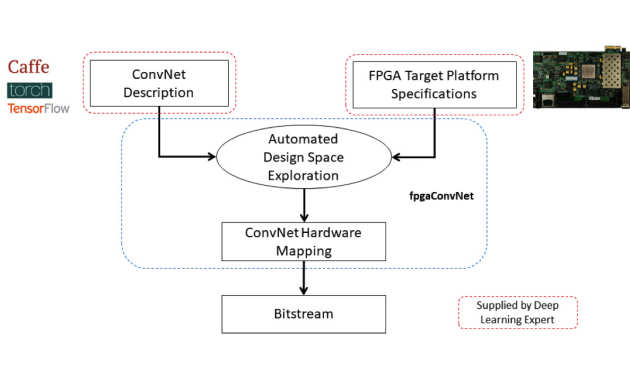
Convolutional Neural Networks (ConvNets/CNNs) are a powerful Deep Learning model which has demonstrated state-of-the-art accuracy in numerous AI tasks, from object detections to neural image captioning. In this context, FPGAs constitute a promising platform for the deployment of ConvNets which can satisfy the demanding performance needs and power constraints posed by emerging applications. Nevertheless, the effective mapping of ConvNets on FPGAs requires Deep Learning practitioners to have expertise in hardware design and familiarity with the esoteric FPGA development toolchains, and therefore poses a significant barrier. fpgaConvNet is a framework that automates the mapping of ConvNets onto reconfigurable FPGA-based platforms. Starting from a high-level description of a ConvNet model, fpgaConvNet considers both the input model's workload and the application-level performance needs, including throughput, latency and multiobjective criteria, in order to generate optimised streaming accelerators tailored for the target FPGA. Read more
Support Vector Machines
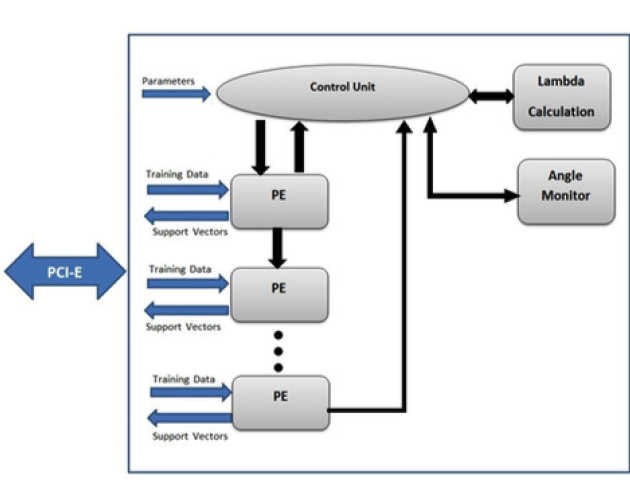
Support Vector Machines (SVMs) is a popular supervised learning method, providing state-of-the-art accuracy in various classification tasks. However, SVM training is a time-consuming task for large-scale problems and prohibits its deployment to situations where the model needs to be constantly refined. In our work, we are addressing the problem of accelerating the training stage of the SVM in order to be able to address large databases, or to address problems with close to real-time constraints (adaptive systems). Towards this direction, we have developed an FPGA-based system based on ensemble learning capable of achieving significant acceleration factors compared to state of the art CPU and GPU based solutions. We have also done work on the classification stage where we have introduced a cascade classifier based on the word-length of the data.
Random Forests
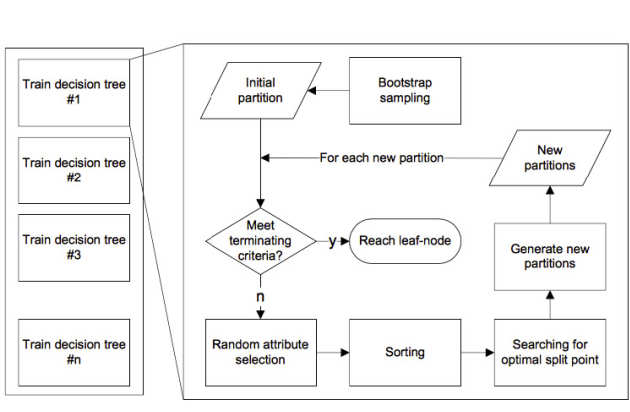
A Random Forest (RF) is an ensemble of decision tree classifiers and it is one of the most widely used supervised learning tools available. In various empirical testings, it demonstrates significant improvement in generalization error over single decision and regression trees by alleviating the overfitting problem and features a fast and robust performance of learning especially for data with noise and missing information. Our group has focused on the acceleration of the training stage of a RF using FPGAs. We have developed a system that can handle large-scale problems by working on them in a batch mode, taking advantage of the large internal memory bandwidth of modern FPGA devices. The performance of the resulting architecture implemented on a modest FPGA is able to achieve a training speed that is comparable to a modest 448-cores GPU implementation and compares favorably with a Python-based implementation running on a 6-cores 2.3GHz CPU. In all cases the proposed architecture features superior performance/power-consumption ratio due to inherent low power consumption in FPGA.
Bayesian Inference
Bayesian inference is a powerful modeling framework which treats all the unknowns in a system as random variables and makes use of probability theory to infer the distributions of the parameters given the observed data. Inferring the unknown distributions of the parameters (i.e. the posterior distribution) requires combining information about the model which comes from the observed data, expressed by the likelihood function, with information coming from some form of expert or prior knowledge about the parameters (expressed by the prior distribution). In the era of Big data and energy-aware systems, my group focuses on the acceleration and performance per energy unit optimization of the main tools in the field such as MCMC and SMC using FPGAs and GPUs. Examples of application can be found in localization of mobile robots and genome analysis.





















































