Surgical Phase Segmentation
Methodology
To locate the action (phase) temporally and spatially, the surgical tool in the scene that performs the action must be detected, and its temporal and spatial dimensions should be modelled. To this end, our methodology consists of three main phases. First, a detection method is applied to detect the surgical tools in each frame. The surgical tools were tracked through frames to form tubes. Then, the surgical tool features are extracted from the tubes using a 3D feature extraction method to connect these features locally (in the same frame) and globally (across frames) using local and global graphs, respectively. We have three types of local graphs, that is, fully-connected, where each of the surgical tool tubes is connected to all the other tubes, scene representing the tree-like structure where all the surgical tool tubes are connected to the scene only, and scene with the same label having the same properties as the scene with the connection between the same surgical tools. This method allows surgical tools to attend to each other in the same frame (in the space domain), which will lead to locating the action and across frames (in the time domain), leading to the detection of the start and end of the action.
Results
This section presents the performance of the proposed phase segmentation model. We demonstrated the performance of all three combinations of models, including a fully-connected graph, scene graph, and scene with the same label graph. For each graph, we selected four different sequence lengths as local graphs, i.e., 12, 18, 24, and 30 frames, as presented in Figures 1, 2, and 3.
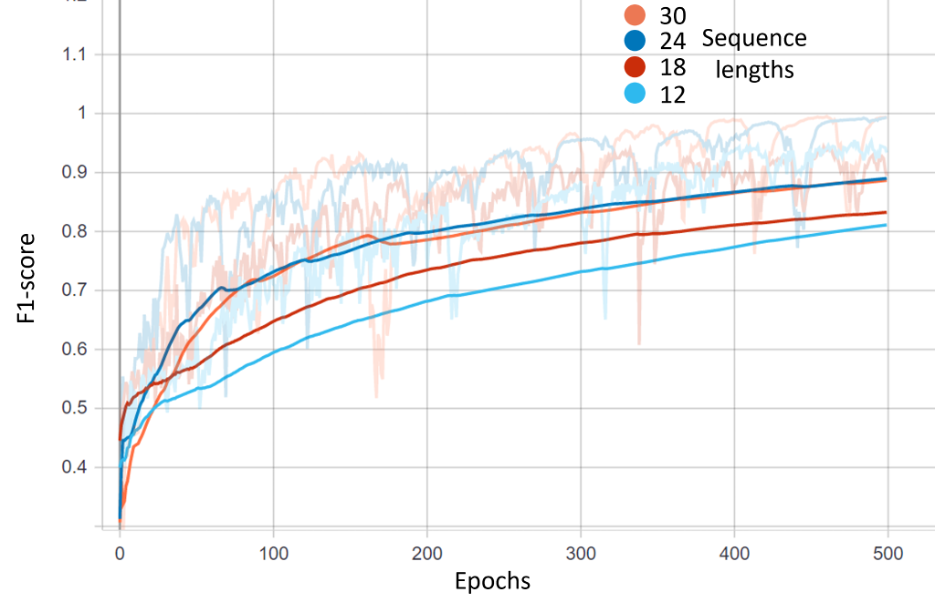 Figure 1: Resuls for fully-connected graph
Figure 1: Resuls for fully-connected graph
 Figure 2: Results for scene graph
Figure 2: Results for scene graph
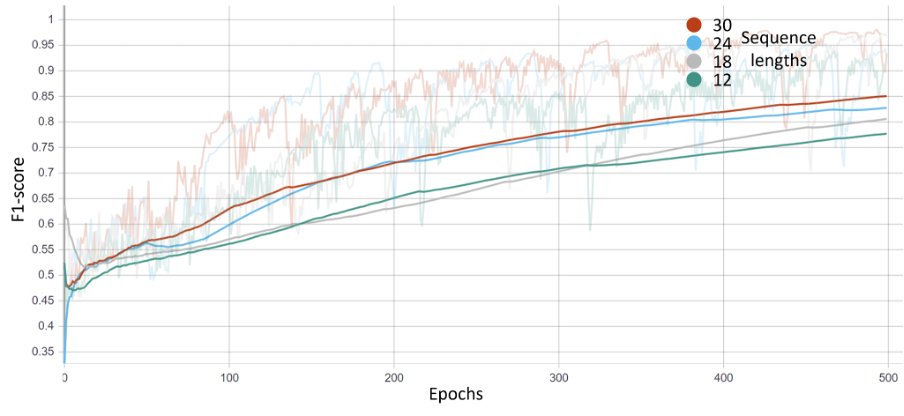 Figure 3: Scene with same agent labels graph
Figure 3: Scene with same agent labels graph



Contact Us
The Hamlyn Centre
Bessemer Building
South Kensington Campus
Imperial College
London, SW7 2AZ
Map location