3D point-cloud detection of operating room staff and surgical instruments
3D Detection
The results presented here can also be found in our paper: https://arxiv.org/abs/2209.05056
One of MAESTRO’s tasks is detecting medical staff and tools in the 3D space, which provides a better spatial understanding of the operating room. This document explains the relevant aspects of working with 3D detection within the MAESTRO project.
1) Data Preparation
Data Collection
The dataset consists of pointclouds extracted after calibrating and combining 8 Azure Kinect RGB-D cameras; each has a 1 MP Time-of-flight (Microsoft Team, n.d.). We used eight cameras to cover all angles of the operating scene. The collected dataset consists of 4 sessions; each has 4000 pointclouds. For the first training, we used 150 pointclouds. Below is a sample of these pointclouds.

Figure 1, Sample of Pointcloud
Data Annotation
We annotated the pointclouds manually by drawing a 3D bounding box. The object of interest was humans with the class name ‘Human’. We used an online annotating platform called Supervisley (shown in Fig. 2) (Supervisely: Unified OS for Computer Vision, n.d.), which has the advantage of copying bounding boxes across frames which, in turn, allows a faster annotation procedure. Furthermore, it has a taskforce environment that splits the annotation work among annotators to supervise and validate the annotations by the reviewers or admins.
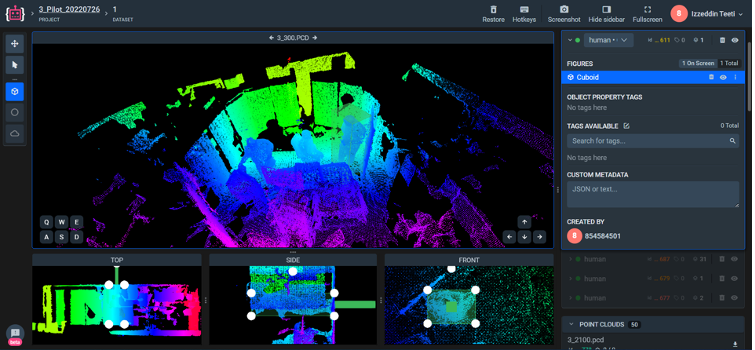
Figure 2, Supervisely interface for 3D annotations
Data Preprocessing
- We downsampled the combined pointclouds to end up with pointclouds of smaller size, which will also take less time to process than the original ponitclouds.
- Then we converted the pointclouds from .ply format to .pcd format, which is the form that Supervisley accepts.
- After annotating the pointcloud, we downloaded them along with their annotations. Then both the pointclouds and their annotations were converted from .pcd and .json formats to .bin and .txt formats, respectively. This is because most of the 3D detection models were trained and tested on Autonomous Driving datasets like KITTI(Geiger et al., 2012), nuScenes (Caesar et al., 2020), and Waymo(Addanki et al., 2021), which have their pointclouds in .bin format.
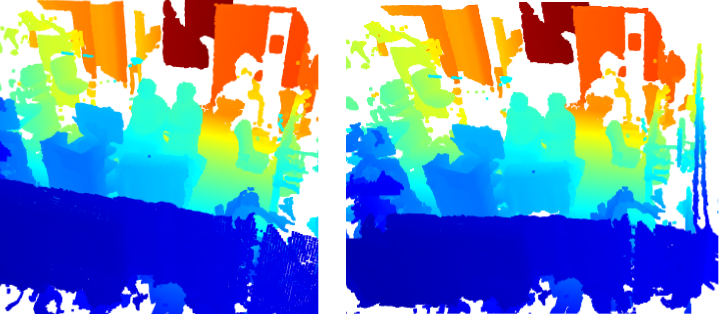 Figure 3, Pointcloud in PCD format Figure 4, Pointcloud in bin format
Figure 3, Pointcloud in PCD format Figure 4, Pointcloud in bin format
2) Methodology
PV-RCNN
We used an off-the-shelf 3D detector called PV-RCNN(Shi et al., 2020). 3D detection models can be categorised into two main categories, Point-based and Voxel-based models. PV-RCNN has integrated the advantages of both categories into one model. The structure of PV-RCNN is shown below.
The model starts with voxelizing the input, dividing it into smaller chunks of pointclouds. The voxels are then fed into the 3D sparse convolutional encoder to extract multi-scale semantic features and generate a 3D object proposal. Using a novel voxel set abstraction module, the extracted voxel-level features at multiple neural layers are summarised and aggregated to form a set of key points. Then the keypoint features are aggregated to the ROI-grid points to extract proposal-specific features. Finally, a two-head, fully connected network refines the proposed boxes and predicts a confidence score.
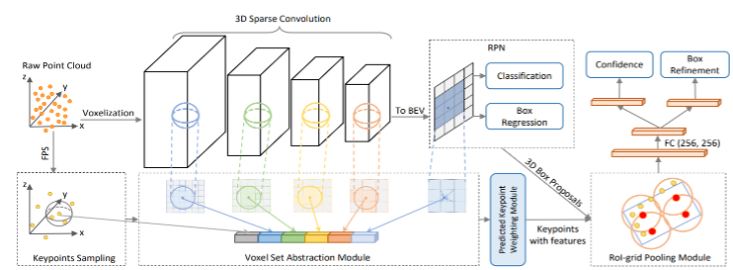 Figure 5, PV-RCNN structure [Shi et al, 2020]
Figure 5, PV-RCNN structure [Shi et al, 2020]
Our modification
As mentioned earlier, most 3D detectors (including PV-RCNN) are designed to work outdoors, specifically for autonomous driving applications/detection. The figure below shows the significant difference between AV pointclouds against MAESTRO pointcloud. In MAESTRO, Humans are represented by a high number of points in a dense configuration (because they are close to the sensor), and the dimensions of humans are large compared to the size of the environment (operating room). While in AV applications, humans are represented by a low number of relatively sparse pints and the dimensions of humans are relatively small compared to the environment (outdoor). As a result, we had to modify many parameters to cope with the inherent differences between human representations and environments.
- Create a new python class and yaml file for a custom dataset (MAESTRO).
- The classes of interest. Currently, we are interested in detecting humans only.
- Point Cloud Range: The x, y, and z ranges of interest. Those were in order of tens of meters in the original AV dataset. However, for MAESTRO, the range is limited to the operating room size, which is a few meters.
- Voxel Size. The same rationale of the previous point, in the original AV datasets, the outdoor environment is significant, so the voxels are large. The environment is significantly smaller in the MAESTRO dataset, so we minimised the voxel size.
- Anchor sizes. The starting point of the proposed bounding box. This can be decided based on our prior knowledge about the size of a human. We changed to the average dimension of a human in the MAESTRO pointcloud.
- Other dimensions and parameters so that the dimensions of the tensor within the model are consistent (the dimension of the output of a certain layer equal the dimension of the input of the next layer).
 Figure 6, Humans in KITTI dataset Figure 7, Humans in MAESTRO dataset
Figure 6, Humans in KITTI dataset Figure 7, Humans in MAESTRO dataset
3) Experiments and Results
Experimental Setup
We trained the model using one 12 GB VRAM Nvidia GTX 1080 GPU. The training time was 3 hours on average.
Hyperparameter Settings
Most deep learning-based models are sensitive to hyperparameters, and the accuracy of the results depends heavily on the right choice of hyperparameters value. For our training, we used the following values:
|
Hyperparameter |
Value |
|
Batch Size |
2 |
|
Num Epochs |
80 |
|
Optimiser |
ADAM |
|
Learning Rate |
0.01 |
|
Weight Decay |
0.01 |
|
Momentum |
0.9 |
Preliminary Results
The following figure shows a sample of the 3D detection results. We can see that the model detected two humans out of 4 in each image. This is due to the low number of training samples. Usually, 3D detection models are trained with 7000 samples, while we used only 150 for the preliminary experiment. Therefore, the following training batch will contain at least five times the number used for this batch.
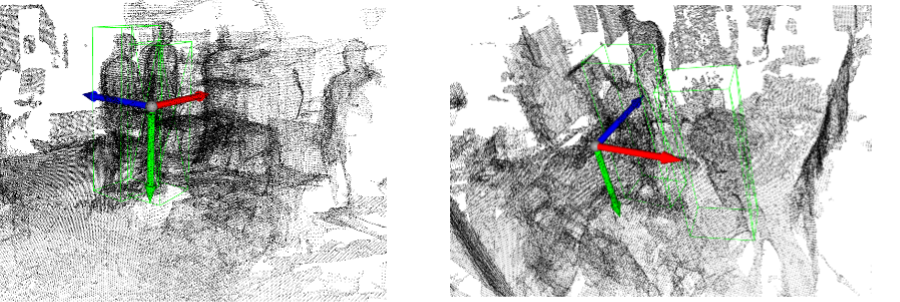 Figure 8, Samples of 3D detection results
Figure 8, Samples of 3D detection results
4) Future Directions
After understanding the 3D detection problem and modifying models to work with our custom dataset, in the future, we aim to increase the number of instances in the dataset to increase its accuracy. We also aim to include more classes other than ‘human’.
References
Addanki, R., Battaglia, P. W., Budden, D., Deac, A., Godwin, J., Keck, T., Li, W. L. S., Sanchez-Gonzalez, A., Stott, J., Thakoor, S., & others. (2021). Large-scale graph representation learning with very deep GNNs and self-supervision. ArXiv Preprint ArXiv:2107.09422.
Caesar, H., Bankiti, V., Lang, A. H., Vora, S., Liong, V. E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., & Beijbom, O. (2020). nuscenes: A multimodal dataset for autonomous driving. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11621–11631.
Geiger, A., Lenz, P., & Urtasun, R. (2012). Are we ready for autonomous driving? the KITTI vision benchmark suite. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 3354–3361. https://doi.org/10.1109/CVPR.2012.6248074
Microsoft Team. (n.d.). Buy the Azure Kinect developer kit. Retrieved September 11, 2022, from https://www.microsoft.com/en-gb/d/azure-kinect-dk/8pp5vxmd9nhq?activetab=pivot%3aoverviewtab
Shi, S., Guo, C., Jiang, L., Wang, Z., Shi, J., Wang, X., & Li, H. (2020). PV-RCNN: Point-voxel feature set abstraction for 3D object detection. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 10526–10535. https://doi.org/10.1109/CVPR42600.2020.01054
Supervisely: unified OS for computer vision. (n.d.). Retrieved September 11, 2022, from https://supervise.ly/



Contact Us
The Hamlyn Centre
Bessemer Building
South Kensington Campus
Imperial College
London, SW7 2AZ
Map location